
The 2026 AI Agent Stack, Drawn from Scratch
Six layers, two rails, and one rule: add a layer only when something specific breaks.


(references to article listed at the bottom)
Building an AI demo is easy - shipping one to real users is harder. Microsoft Foundry helps developers build and manage AI apps across models like GPT, Claude, Mistral, DeepSeek, Llama, and more. With Foundry IQ, your agents can connect to real business context and answer from your own data. You can start directly inside VS Code with the Foundry Toolkit.
A backend team starts building what sounds like a simple internal agent.
The agent needs to answer support questions, look up a customer record, and call one refund endpoint. That is it.
But three weeks later, the system has grown into something much bigger. There is a graph runtime, persistent state, retries, custom tool wrappers, a vector database, memory, tracing, dashboards, and a few “future-proof” abstractions nobody is using yet.
The agent itself is still simple, the architecture around it is not.
This is the trap most teams fall into with agents. They do not fail because they picked a bad model or used the wrong framework. They fail because they add layers before they can name the problem each layer is supposed to solve.
This article expands on Letta’s 2024 agent-stack diagram and Paolo Perrone’s 2026 O’Reilly update. It offers a new perspective from a backend engineer’s view.
The goal is not to memorize every tool in the ecosystem.
The goal is to understand what each layer does, when you need it, and when you are over-building.
The most important rule is simple: start with the smallest stack that solves the problem. Add a layer only when something specific breaks.
Most Teams Do Not Need the Full Stack on Day One
The biggest mistake with agents is not starting too small, it is starting too big.
A basic production agent might only need three things:
A model that can reason through the request.
A few tools it is allowed to call.
A way to retrieve the private data it needs.
That alone can solve a lot of real business problems.
But teams often skip straight to the advanced version. They add orchestration because agent graphs look serious. They add memory because every demo talks about personalization. They add multi-agent workflows because the architecture diagram looks better. They add observability after everything is already hard to debug.
The result is a strange kind of complexity. The agent is still doing a simple job, but the system around it now has six layers, three vendors, custom state, and a retry strategy nobody fully trusts.
That is why the stack needs to be treated like a map, not a checklist. You do not need every layer just because the layer exists. You need the layer when you can point to a specific failure and say, “This is the thing that fixes it.”
If users keep repeating preferences, you probably need memory. If one model call cannot handle the workflow, you probably need orchestration. If tool calls can affect production data, you need governance. If prompt changes are shipping on vibes, you need evals.
But if the agent answers questions, calls one API, and works reliably, do not make it more complicated just to feel more “agentic.”
So let’s start where every agent starts: the loop.
The Loop Is the Agent. The Stack Keeps It Standing.
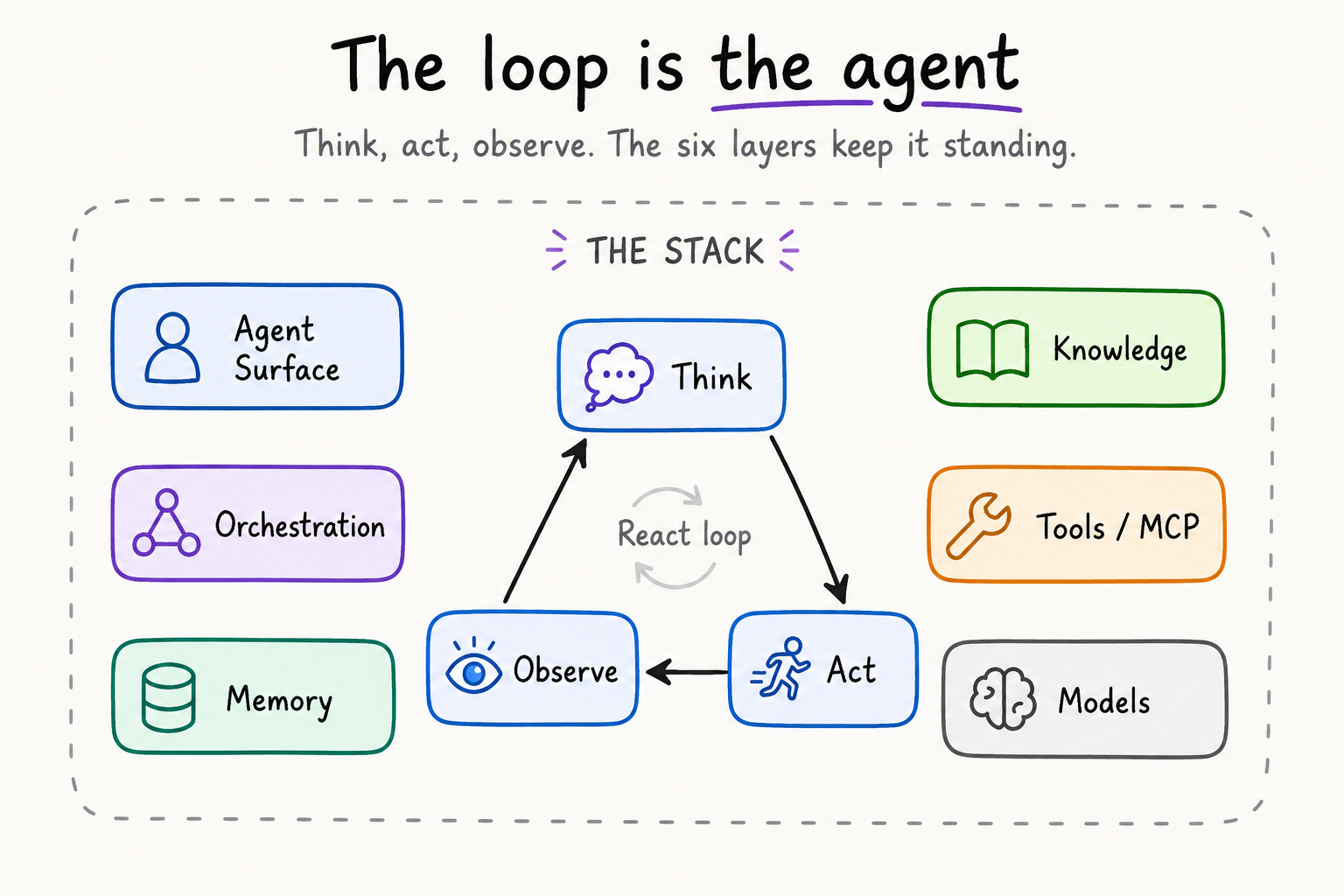
Every agent, no matter how complex, runs the same core loop: think, act, observe. The model reasons about a task, takes an action (calls a tool, writes to memory), observes the result, and loops until done, a pattern also called ReAct, short for reason plus act. Everything else in this article is infrastructure that makes that loop run reliably with real users hitting it. The stack is not the agent; the stack is what keeps the agent from falling over when production traffic arrives.
One more distinction matters. The agent stack is not the large language model (LLM) stack. The LLM stack serves model inference: graphics processing units (GPUs), batching, quantization, and request routing across servers like vLLM and Ollama. The agent stack sits above that, governing what happens between the model and the real world: tools, memory, orchestration, and eval. Letta’s original diagram already drew this line.
Now for the map itself.
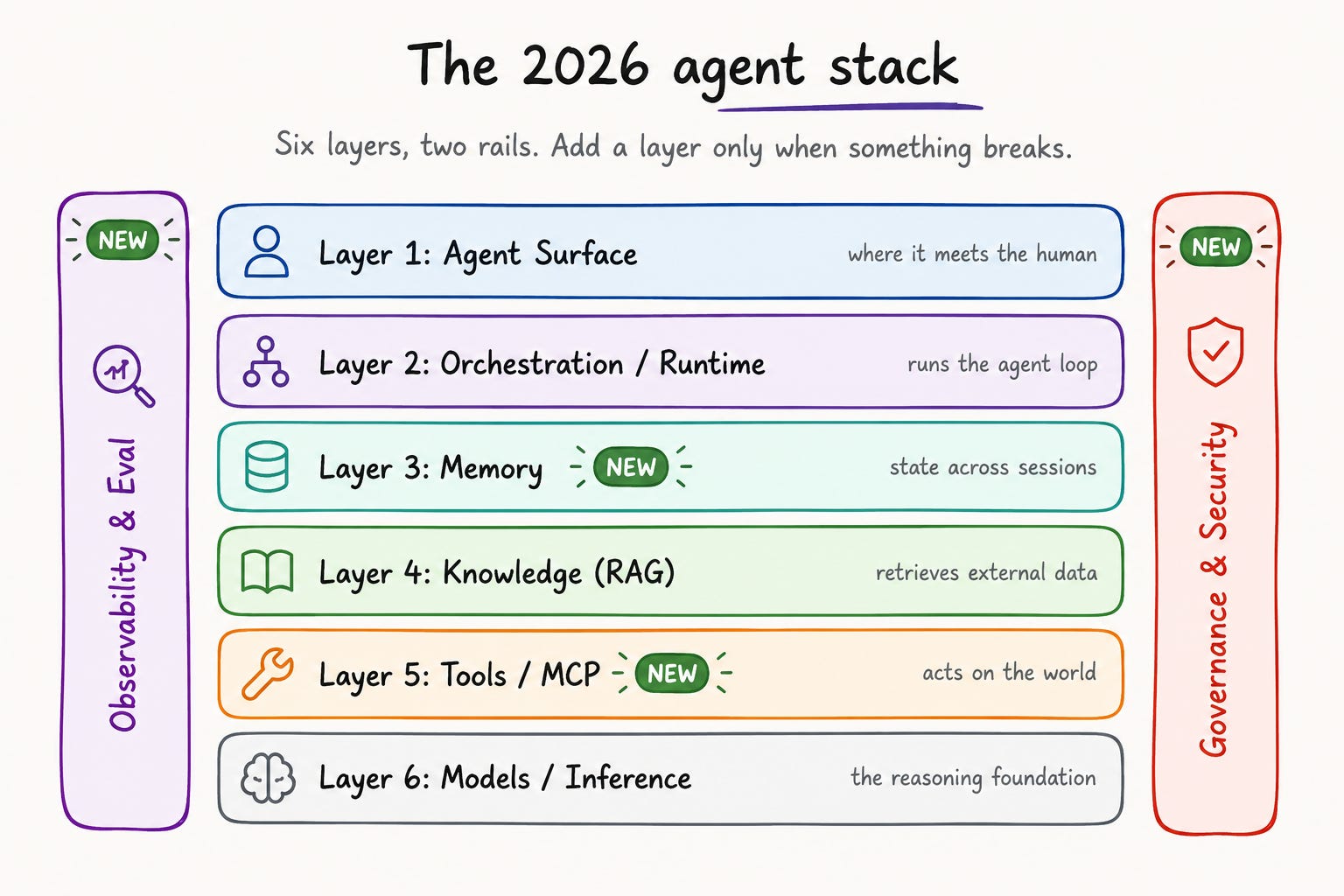
The Map: Six Layers and Two Rails
The 2026 agent stack has six horizontal layers. These layers are wrapped by two vertical rails that touch each layer. Each layer does one job; the rails cut across all of them. Think of it as a network stack. Each layer has one job and connects clearly to the layer below. This way, you focus on one layer at a time. If something breaks, you know exactly which layer to check.
Here is the full stack, top to bottom:
Layer 1: Agent Surface -- where the agent shows up for the human.
Layer 2: Orchestration / Runtime -- the control plane that runs the agent loop.
Layer 3: Memory -- what the agent remembers across steps, sessions, and users.
Layer 4: Knowledge -- this is external information the agent gets. It’s often known as retrieval-augmented generation (RAG).
Layer 5: Tools / MCP -- how the agent acts on the outside world.
Layer 6: Models / Inference -- the foundation models powering reasoning.
And the two rails, running vertically across every layer:
Rail A: Observability and Eval -- traces, metrics, and quality measurement.
Rail B: Governance and Security -- permissions, audit, and human-in-the-loop controls.
Four things changed since Letta drew the original. MCP emerged as a distinct tool-connectivity standard that did not exist in 2024. Memory split from knowledge into its own layer, where it used to be lumped in with the vector database. Eval became a first-class concern that was not on the original map at all. And provider-native SDKs absorbed several layers into single APIs. Different authors slice the stack differently, but most modern agent systems are converging around the same core concerns: models, tools, knowledge, memory, orchestration, eval, and governance.
Now we walk it bottom to top, starting at the foundation, because nothing above holds up without it.
Layer by Layer
Each layer gets the same four beats: what it is, what lives here, the 2026 shift, and when you need it. Let’s dive in.
Layer 6: Models and Inference
What it is. The foundation, where reasoning happens. Without a capable model, nothing above holds up.
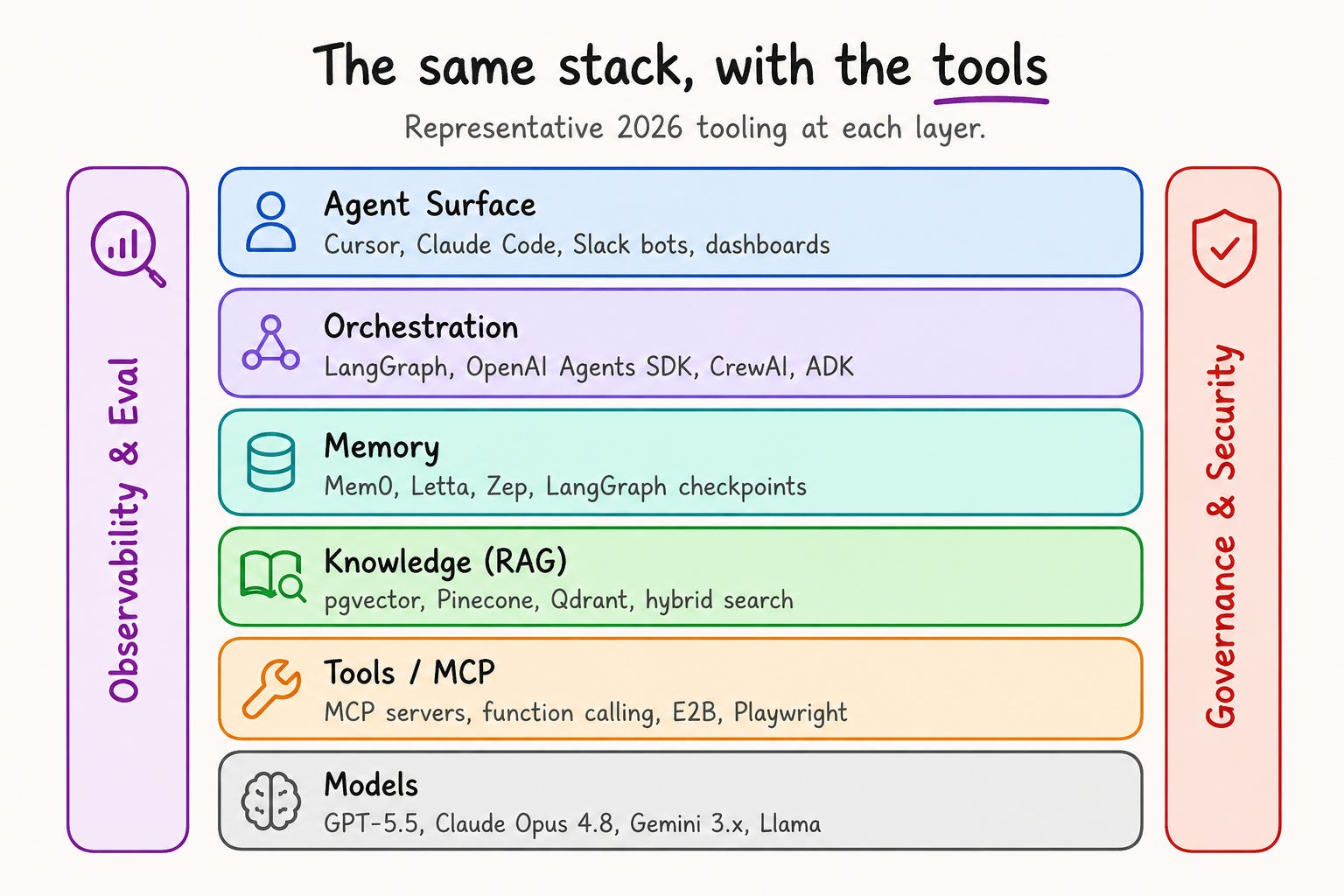
What lives here. The frontier model layer changes quickly, so avoid hard-coding your architecture around one provider or one model name. In 2026, examples include OpenAI’s GPT-5.5 family, Anthropic’s Claude 4.x models, and Google’s Gemini 3.x models. You can self-host these open-weight models: Llama, Mistral, and DeepSeek. Use Ollama, vLLM, or a cloud inference provider to serve them.
The 2026 shift. Production agents rarely use a single model. The pattern is model routing: which sends each request to the cheapest model that can handle it. Classification and triage use a small, quick model. Hard reasoning relies on a frontier model. Embedding and evaluation have their own dedicated models. Research on model routing, including RouteLLM, shows why this pattern matters: routing can significantly reduce cost while preserving most of the quality of a stronger model on many tasks. Specialization boosts cost and performance. However, you now have multiple models to connect instead of just one.
When you need it. Always; it is the foundation. But here is the insight that is easy to get wrong: upgrading the model rarely fixes a failing agent. If memory doesn’t have the right context, tools give bad inputs. Orchestration might route incorrectly. In these cases, a bigger model won’t help you. Diagnose the failing layer before you reach for an upgrade.
Layer 5: Tools and MCP
What it is. How the agent acts on the outside world. APIs, databases, file systems, web browsers, and code execution environments.
What lives here. MCP servers as the standard protocol for tool connectivity. Provider-native function calling. Browser automation through Browser Use or Playwright. Code sandboxes from E2B and Modal. And workflow-level connectors like Zapier and n8n for triggers.
The 2026 shift. MCP is the big change, and it is why this layer did not exist as a distinct category 14 months ago. Anthropic launched it on November 25, 2024. This standard connects AI assistants to data systems. Before this, each tool integration was custom-made and hard to scale. Here is the math it fixes. With N agents and M tools, each needing a custom integration, you have N times M connectors. But, if both sides use one protocol, it simplifies to N plus M. MCP operates using JSON-RPC 2.0 messages. It negotiates capabilities between the client and server. It uses two methods: stdio for local servers and HTTP with Server-Sent Events for remote servers. The series’ MCP article covers the protocol in depth.
When you need it. The moment the agent does anything beyond generating text. If it reads a database, calls an API, writes a file, or browses the web, you are at this layer.
Layer 4: Knowledge (RAG and Retrieval)
What it is.
External information the agent retrieves at query time includes:
Your documents
Your database
Your knowledge base
The agent does not know this from training; it looks it up, which is what RAG does.
What lives here. Vector databases like pgvector, Pinecone, Qdrant, and Chroma. Embedding models and document loaders are key. Chunking pipelines help organize data. Retrieval strategies decide what you get back. Three strategies matter. Sparse retrieval often uses BM25 (Best Match 25). It is great for exact-match queries. This includes identifiers, error codes, and rare terms that embeddings have not seen. Dense retrieval uses embeddings for semantic matching. Hybrid search uses Reciprocal Rank Fusion (RRF). This method merges ranked lists by their rank. It does not rely on raw scores. This avoids scale mismatches between the two approaches. RRF has become one of the common ways modern search systems combine sparse and dense retrieval results. It is supported or discussed across major search systems such as OpenSearch, Elasticsearch, Azure AI Search, MongoDB Atlas, and Weaviate.
The 2026 shift. Knowledge and memory used to be the same layer; they are now different problems. Knowledge is external data that the agent can access. Memory is the agent’s own state that it writes and retrieves. A second insight saves a lot of wasted effort: in many RAG failures, the bottleneck is not the vector database itself. It is retrieval quality: which chunks were found, how they were ranked, and whether the right context reached the model. LongMemEval research shows that basic long-context retrieval does well. It works best with large context windows. This highlights the importance of what you retrieve. So treat retrieval as an evals problem first and an infrastructure problem second.
When you need it. When the agent must answer questions about your specific data that is not in the model’s training set. The series’ RAG article covers retrieval architecture in depth.
Layer 3: Memory
What it is. What the agent remembers across steps, sessions, and users. Not the external knowledge it retrieves (that is Layer 4); this is the agent’s own persistent state.
What lives here. Mem0 positions itself as a memory layer for AI apps and reports strong developer adoption, including GitHub stars and package-download traction. Letta, once known as MemGPT, was created by the team at UC Berkeley’s Sky Computing Lab. Zep, a temporal knowledge graph engine that tracks when a fact became valid and when it went stale. Plus LangGraph checkpointing and custom stores.
The 2026 shift. This is the layer that split from knowledge in 2025 and 2026. An agent that spans sessions needs a memory system. This system must know what to keep, what to age out, and what to bring back into context. This is different from vector retrieval.
New benchmarks are now in use:
LoCoMo tests very long-term conversational memory.
LongMemEval checks multi-session and temporal reasoning with 500 question.
BEAM operates at 1-million and 10-million-token scales, which can’t be brute-forced with a larger context window.
The larger lesson is that memory systems are not interchangeable. Some are optimized for recalling user facts. Others are designed around temporal reasoning, changing relationships, and stale information. Zep’s temporal-knowledge-graph approach is one example of that direction. Some benchmarks show strong results for Zep on temporal queries, but vendor-adjacent benchmarks should be treated carefully. The strong part is the architecture, not the score. Zep’s Graphiti core models fact-validity windows. This makes temporal reasoning a key feature, not an afterthought. Memory is becoming its own product category, with Mem0 raising $24 million and Letta a $10 million seed.
When you need it. Track user preferences over time when agents cover multiple sessions. Also, gather project context over weeks. A single-session chatbot doesn’t need memory. But an agent managing your codebase over months does. There is a hard problem nobody mentions: deciding what to remember is harder than storing it. Mem0 states that a well-recalled memory about a user’s employer is right until they switch jobs. After that, it becomes confidently incorrect. Confidently wrong is the dangerous kind, because it is hard to detect.
Layer 2: Orchestration and Runtime
What it is. The control plane contains the agent loop in code. It includes the planner, executor, tool dispatcher, state machine, and streaming surface.
What lives here. LangGraph, which reached version 1.0 on 22 October 2025 and runs in production at Klarna, Uber, LinkedIn, and JPMorgan.
The provider SDKs include:
OpenAI’s Agents SDK (March 2025, based on the “handoff” concept)
Google’s Agent Development Kit
Microsoft’s Agent Framework
Anthropic’s Claude Agent SDK
The open frameworks include:
AutoGen (now part of Microsoft’s framework)
CrewAI for role-based orchestration
Agno for lightweight swarms
DSPy, which treats prompting like compilation.
Plus loop-level pieces in coding harnesses: Claude Code hooks, Codex Automations.
The 2026 shift. The runtime layer commoditized faster than expected. A year ago, choosing an agent runtime felt like a major architectural decision. In 2026, the choice is increasingly practical: what fits your language, your deployment model, your provider, and the complexity of the workflow?
Provider SDKs are combining orchestration into single APIs. Multi-agent patterns now follow four standard styles:
Graph-based (LangGraph)
Role-based (CrewAI)
Handoff-based (OpenAI Agents SDK)
Hierarchical (Google ADK)
When you need it. When the agent has more than one step, it needs state between steps. It also requires coordination with other agents. The message is clear: you write logic to chain LLM calls, manage retries, or pass outputs between them. This is the same over-engineering pattern from the opening example: a simple agent doing a simple job, surrounded by architecture it has not yet earned. The hard problems are shared state, error recovery, and streaming partial results. The series’ LangChain and Loop Engineering articles go deeper.
Layer 1: Agent Surface
What it is. Where the agent shows up for the human. The interface.
What lives here. Chat interfaces. IDE coding agents include Cursor, Claude Code, OpenAI Codex, and Devin Desktop. Devin Desktop is Cognition’s renamed Windsurf desktop product, relaunched on June 2, 2026. Slack bots, browser extensions, dashboard widgets, approval queues, and email integrations.
The 2026 shift. The set of meaningful surfaces is far wider than “chat window.” Aishwarya Naresh Reganti notes that agents now exist in many places. They’re in Cursor, Slack channels, browsers, and enterprise dashboards. They’re also appearing more in approval queues that send requests to people when policies require it. The spectrum ranges from light to heavy. Light is a Slack channel talking to an agent. Heavy is a coding harness, like Claude Code. It merges the whole agent loop into the interface.
When you need it. Always, though it carries more weight than most realize.
Surface design shapes capabilities:
An agent in a chat window receives text.
An agent in an IDE gets code context.
An agent in an approval queue handles structured decisions.
Now the two rails, the verticals that cut across every layer above.
Rail A: Observability and Eval
What it is. Traces, metrics, quality measurement, and cost tracking, applied to every layer.
What lives here. LangSmith, with the deepest framework integration. Langfuse, the open-source leader, acquired by ClickHouse in January 2026. Arize Phoenix, built on OpenTelemetry tracing. And Braintrust, for eval-driven development with continuous-integration gates.
The 2026 shift. Eval emerged as the most under-built and most consequential layer. Gartner’s Market Guide for AI Evaluation and Observability Platforms was released on February 2, 2026. It says that by 2028, 60% of software engineering teams will use these platforms. This is a big jump from 18% in 2025. The gap between logging and real evaluation is large. LangChain’s State of Agent Engineering report states that 89 percent of organizations have observability. This helps them track their systems. But only 62 percent have detailed tracing. About half of the organizations run offline evaluations. Most have logs; far fewer have eval-grade observability.
When you need it. Earlier than you think. The honest recommendation: build the eval harness before you build the second agent. With real observability, you can tell in five minutes if your last change helped or hurt your agent on the eval set. If you can’t do this, it’s just logging pretending to be observability. Debugging two agents passing context is tough. With five agents, it becomes impossible unless you trace every handoff.
Rail B: Governance and Security
What it is. Permissions, audit trails, human-in-the-loop controls, and compliance.
What lives here. Role-based access control (RBAC) for agent tool access. Audit logging. Approval workflows. Prompt-injection defenses. The OWASP MCP Top 10 is the first risk list focused on MCP security. It points out problems such as token mismanagement, tool poisoning, shadow MCP servers, context over-sharing, and command injection.
The 2026 shift. This layer barely showed up in the 2025 guides; the original Letta diagram had no governance layer at all. In 2026 it is what separates a pilot from a production deployment. The threat is real. In early 2026, researchers reported over 30 CVEs aimed at MCP servers, clients, and tools. Notably, 43 percent were shell injections. Compliance pressure is clear. A Grant Thornton survey of 950 executives found that 78 percent don’t think they can pass an independent AI governance audit in 90 days. Also, the EU AI Act becomes fully enforceable for high-risk systems in August 2026.
When you need it. The moment the agent accesses production data, customer data, or makes decisions with real-world effects. Every enterprise contract starts with the governance conversation now.
That is the full map. Now the part that keeps you from building all of it.
Start Minimal. Add Layers Only When the Failure Is Obvious.
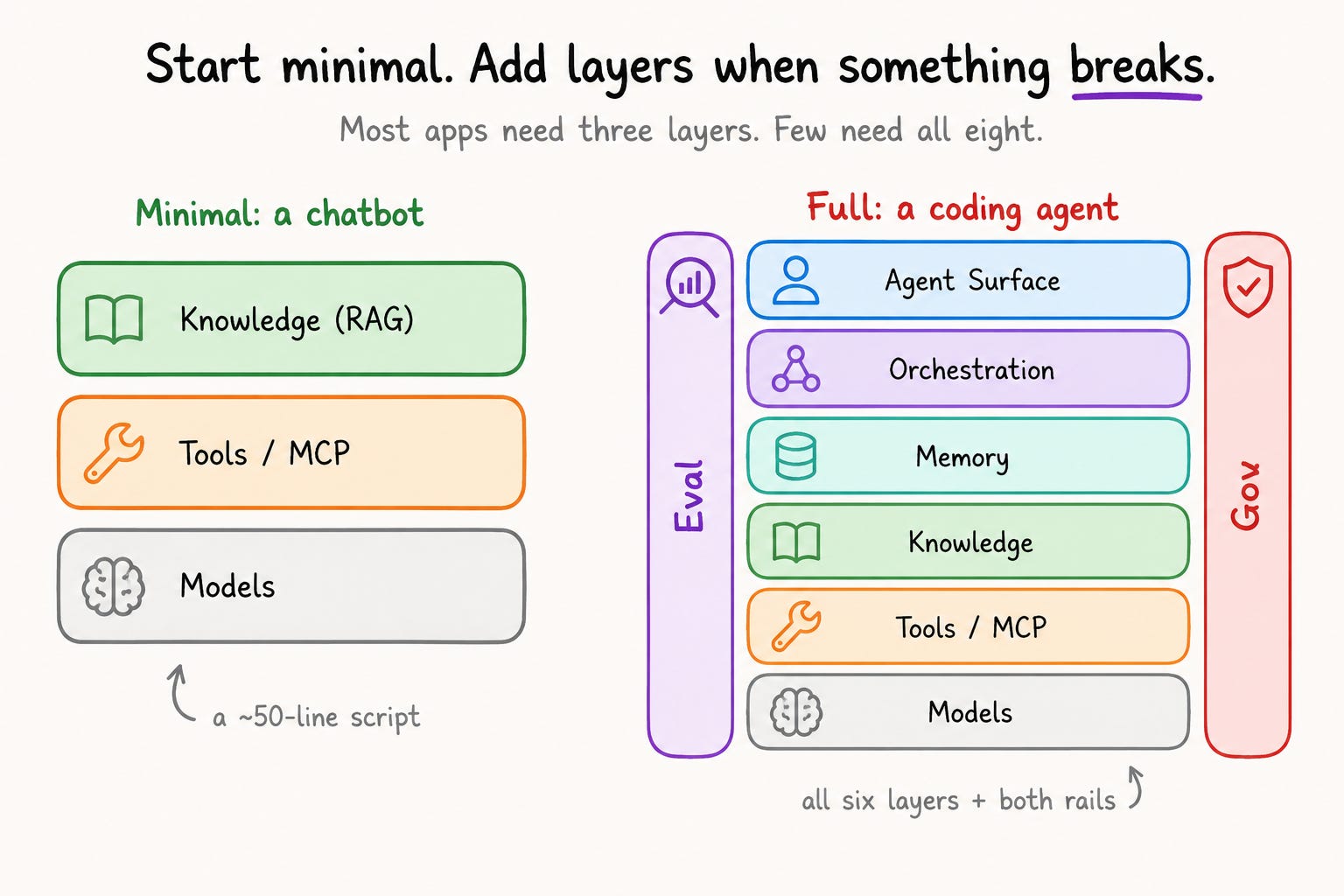
Here is the practical way I would build most agents. Start with three layers:
Model.
Tools.
Knowledge.
That means one model call or a small number of model calls, a limited set of tools the agent can use, and retrieval over the data it needs to answer from.
For many use cases, that is enough.
A customer-support agent may need product docs, account lookup, and a refund endpoint.
An internal engineering assistant may need documentation, GitHub issues, and read-only access to service metadata.
A sales-support agent may need CRM lookup, pricing rules, and approved collateral.
None of those automatically require long-term memory, multi-agent workflows, custom orchestration, or a dedicated agent platform.
Add those pieces when the failure becomes clear. Add orchestration when the workflow has real branching, retries, approvals, or state that needs to survive across steps.
The signal is not “we want to use LangGraph.” The signal is “we are hand-writing too much glue code to coordinate model calls and tool calls.” Add memory when the agent needs to remember facts across sessions. The signal is not “memory sounds cool. The signal is “users keep repeating things the agent should already know.”
Add evals when you cannot tell whether a change helped or hurt. The signal is not “we have logs.” The signal is “we changed the prompt and have no measurable idea whether the agent got better.”
Add governance when the agent touches customer data, production systems, money movement, permissions, or anything with real-world consequences.
The signal is not “security review is coming eventually.” The signal is “we would be nervous if this agent did the wrong thing automatically.”
Add multi-agent design last. The signal is not “multi-agent sounds advanced.” The signal is “one agent has too much context, too many tools, or too many responsibilities to do the job cleanly.”
This is the rule I would keep coming back to: Do not add architecture because it exists.
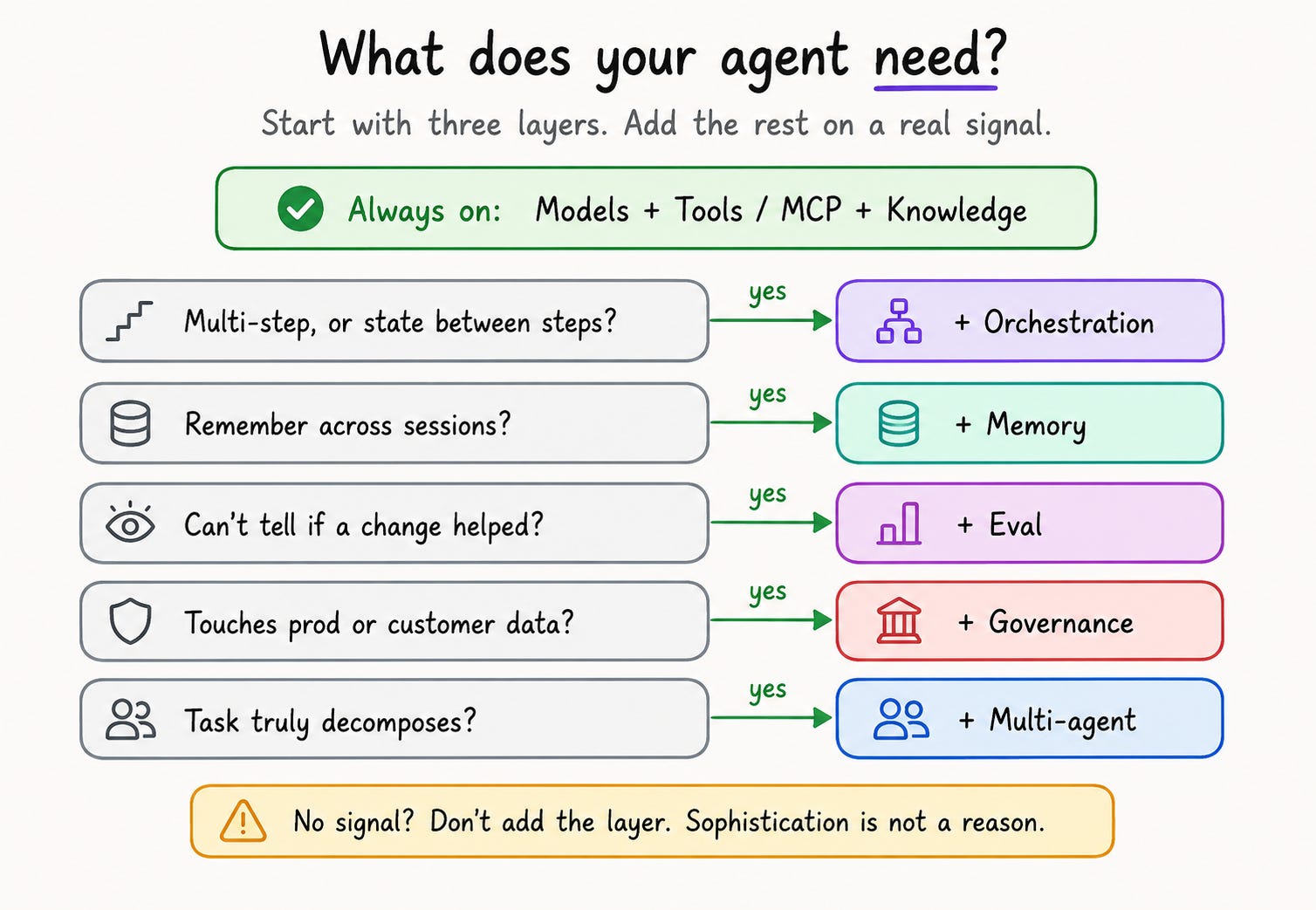
Add architecture because a specific failure forced you to.
Coding Agents Are the Existence Proof
To see the complete stack assembled and working, study a coding agent. Claude Code, Cursor, Codex, and Devin Desktop are the most developed apps among all six layers and both rails. They are currently running in production. Map it onto one and the abstraction turns concrete:
Models: frontier inference at scale (GPT-5.5, Claude Opus 4.8 and Sonnet 4.6, Gemini 3.x), serving requests at massive volume.
Tools: file-system access, terminal execution, web search, and MCP servers.
Knowledge: codebase indexing, documentation retrieval, and dependency graphs.
Memory: project context, user preferences, and conversation history across sessions.
Orchestration: multi-step plan, implement, test, iterate, plus subagents.
Eval: verification loops that check whether the code compiles, the tests pass, and the diff matches the request.
The stack stops being abstract the moment you map it onto a tool you use every day. The coding agent is proof that all six layers and both rails can run together at scale. So the model works today. The harder question is what it looks like next year.
The Stack Is Going to Collapse
Adoption is no longer the question. LangChain’s State of Agent Engineering report reveals that 57% of organizations use agents in production now. This is an increase from 51 percent last year. Additionally, 30 percent are working on deploying agents. The tooling is exploding too: StackOne maps more than 120 agentic tools across 11 categories.
Every technology platform follows the same arc. It starts off fragmented, with many tools in each layer. Then, it narrows down to a few top tools per layer. Finally, it collapses into platforms as providers merge entire layers into integrated offerings. We are in early consolidation. The runtime layer commoditized first. Memory is consolidating now, with Mem0, Letta, and Zep forming a distinct funded category. Eval is next. Provider SDKs are the engine, pulling tool calling, memory, and basic eval into single APIs.
My forecast, and it is a forecast rather than a measured number: by 2027, most teams will not build each layer separately. They will get an increasingly opinionated stack from their model provider. This works for most cases. However, a few users running agents at scale may face issues with the defaults. They will still need to create custom solutions. This aligns with O’Reilly’s argument in “Case Against Building Your Own Agent Platform”.
Stay honest about the timeline. Letta’s 2024 diagram and Perrone’s 2026 edition show a big change in the tool list. The 2028 stack will be different from the 2026 one in ways we can’t foresee. The layer model is the durable part, not the current tool list.
What to Take Away
The agent stack has six layers in 2026. At least three of these layers—MCP, memory as a distinct layer, and eval—did not exist as separate categories a year and a half ago.
Start with a basic stack of models, tools, and knowledge for most tasks. Add a layer only when something specific fails. This article is not here to tell you what to build. It is here to give you the map, so you know where you are standing.
Where this fits in the series
This article is the map; the others are the deep dives, each a closer look at one or two layers:
MCP -- Layer 5 (Tools), the protocol that standardized tool connectivity.
RAG -- Layer 4 (Knowledge), how agents retrieve external information.
A2A -- Layer 2 (Orchestration, multi-agent), how agents from different systems collaborate.
Prompt Engineering -- cross-cutting, how you instruct the models at each layer.
LangChain -- Layer 2 (Orchestration), the framework for composing these layers.
Loop Engineering -- Layer 2 plus Rail A, designing autonomous loops with verification.

Eric Roby
Find me online:
LinkedIn / YouTube / Threads

Article References
This article builds on several sources about the modern AI agent stack, including Letta’s original 2024 agent-stack diagram, Paolo Perrone’s 2026 O’Reilly update, official MCP documentation, provider SDK docs, and recent writing on agent memory, observability, governance, and orchestration.
Core Agent Stack Sources
[1] Paolo Perrone — “The AI Agents Stack (2026 Edition)”
https://www.oreilly.com/radar/the-ai-agents-stack-2026-edition/
[2] Letta — “The AI Agents Stack”
https://www.letta.com/blog/ai-agents-stack/
[3] Paolo Perrone — “The Open-Source Agent Toolkit in 2026”
https://medium.com/data-science-collective/the-open-source-agent-toolkit-in-2026-da66dda36c9b
[4] Pete Johnson — “The Case Against Building Your Own Agent Platform”
https://www.oreilly.com/radar/the-case-against-building-your-own-agent-platform/
[5] Aishwarya Naresh Reganti — “The AI Agent Stack in 2026”
[6] MindStudio — “What Is the Agent Infrastructure Stack? The Six Layers Every AI Builder Needs to Understand”
https://www.mindstudio.ai/blog/agent-infrastructure-stack-six-layers-explained
Protocols, SDKs, and Model Providers
[7] Model Context Protocol Specification
https://modelcontextprotocol.io/specification
[8] Anthropic — “Introducing the Model Context Protocol”
https://www.anthropic.com/news/model-context-protocol
[9] OpenAI — Agents SDK Documentation
https://developers.openai.com/api/docs/guides/agents
[10] OpenAI — “The Next Evolution of the Agents SDK”
https://openai.com/index/the-next-evolution-of-the-agents-sdk/
[11] Anthropic — Claude Models Overview
https://platform.claude.com/docs/en/about-claude/models/overview
[12] Google DeepMind — Gemini Models
https://deepmind.google/models/gemini/
[13] Google — “Gemini 3 Flash”
https://blog.google/products/gemini/gemini-3-flash/
[14] Linux Foundation — “Agent2Agent Protocol Project”
https://www.linuxfoundation.org/press/linux-foundation-launches-the-agent2agent-protocol-project-to-enable-secure-intelligent-communication-between-ai-agents
Memory and Long-Term Context
[15] Mem0 — “State of AI Agent Memory 2026”
https://mem0.ai/blog/state-of-ai-agent-memory-2026
[16] Mem0 — “AI Memory Benchmarks 2026”
https://mem0.ai/blog/ai-memory-benchmarks-in-2026
[17] Mem0 — Series A Announcement
https://mem0.ai/series-a
[18] TechCrunch — “Mem0 Raises $24M…”
https://techcrunch.com/2025/10/28/mem0-raises-24m-from-yc-peak-xv-and-basis-set-to-build-the-memory-layer-for-ai-apps/
[19] Letta — “MemGPT Is Now Part of Letta”
https://www.letta.com/blog/memgpt-and-letta/
[20] PR Newswire — “Letta Raises $10M Seed Financing”
https://www.prnewswire.com/news-releases/berkeley-ai-research-lab-spinout-letta-raises-10m-seed-financing-led-by-felicis-to-build-ai-with-memory-302257004.html
[21] Zep — “Zep Is the New State of the Art in Agent Memory”
https://blog.getzep.com/state-of-the-art-agent-memory/
[22] Atlan — “Zep vs Mem0: Benchmarks, Pricing, and When to Use Each”
https://atlan.com/know/zep-vs-mem0/
[23] LoCoMo — “Evaluating Very Long-Term Conversational Memory of LLM Agents”
https://arxiv.org/abs/2402.17753
[24] LongMemEval — “Benchmarking Chat Assistants on Long-Term Interactive Memory”
https://arxiv.org/abs/2410.10813
Orchestration, Frameworks, and Coding Agents
[25] LangChain — “LangGraph 1.0 Is Now Generally Available”
https://changelog.langchain.com/announcements/langgraph-1-0-is-now-generally-available
[26] LangChain Interrupt — “How JP Morgan Built an AI Agent for Investment Research with LangGraph”
[27] ZenML — “Multi-Agent Investment Research Assistant with RAG and Human-in-the-Loop”
https://www.zenml.io/llmops-database/multi-agent-investment-research-assistant-with-rag-and-human-in-the-loop
[28] Medium — “10 AI Agent Frameworks You Should Know in 2026”
https://medium.com/@atnoforgenai/10-ai-agent-frameworks-you-should-know-in-2026-langgraph-crewai-autogen-more-2e0be4055556
[29] GuruSup — “Best Multi-Agent Frameworks in 2026”
https://gurusup.com/blog/best-multi-agent-frameworks-2026
[30] Future AGI — “What Is Google ADK?”
https://futureagi.com/blog/what-is-google-adk-2026
[31] The New Stack — “Claude Code vs. Cursor vs. Codex vs. Antigravity”
https://thenewstack.io/claude-code-vs-cursor-vs-codex-vs-antigravity-2026/
[32] House of MVPs — “AI Coding Agents Compared”
https://houseofmvps.com/blog/tools/ai-coding-agents-comparison
[33] Lushbinary — “AI Coding Agents & IDEs: The Complete 2026 Comparison”
https://lushbinary.com/blog/ai-coding-agents-comparison-cursor-windsurf-claude-copilot-kiro-2026/
Retrieval, Tools, Sandboxes, and Browser Automation
[34] DigitalApplied — “LLM Model Routing in 2026”
https://www.digitalapplied.com/blog/llm-model-routing-2026-cost-quality-optimization-engineering-guide
[35] BigData Boutique — “Reciprocal Rank Fusion: How It Works and When to Use It”
https://bigdataboutique.com/blog/reciprocal-rank-fusion-how-it-works-and-when-to-use-it
[36] Firecrawl — “AI Agent Sandbox”
https://www.firecrawl.dev/blog/ai-agent-sandbox
[37] Browser Use
https://github.com/browser-use/browser-use
[38] Playwright
https://github.com/microsoft/playwright
Observability, Evaluation, and Governance
[39] LangChain — “State of Agent Engineering”
https://www.langchain.com/state-of-agent-engineering
[40] Comet — “2026 Gartner Market Guide for AI Evaluation and Observability Platforms”
https://www.comet.com/site/blog/gartner-market-guide-february2026/
[41] StackOne — “120+ Agentic AI Tools Mapped Across 11 Categories”
https://www.stackone.com/blog/ai-agent-tools-landscape-2026/
[42] DigitalApplied — “Agent Observability: LangSmith, Langfuse, Arize 2026”
https://www.digitalapplied.com/blog/agent-observability-platforms-langsmith-langfuse-arize-2026
[43] Latitude — “Best LLM Observability Tools for AI Agents”
https://latitude.so/blog/best-llm-observability-tools-agents-latitude-vs-langfuse-langsmith
[44] OWASP — MCP Top 10 Project
https://owasp.org/www-project-mcp-top-10/
[45] OWASP — MCP Top 10 GitHub Repository
https://github.com/OWASP/www-project-mcp-top-10
[46] Practical DevSecOps — “OWASP MCP Top 10”
https://www.practical-devsecops.com/owasp-mcp-top-10/